
If you upgraded to Kubernetes 1.34 and suddenly saw pod failures like short name mode is enforcing, you are not alone.
This post explains what changed, who is affected, and how to mitigate quickly without creating long-term security debt.
What changed in practice
The breaking behavior is linked to CRI-O 1.34 image resolution behavior, not a new Kubernetes API field.
In CRI-O v1.34.0 (released on September 10, 2025), release notes include a change to enforce short-name resolution ambiguity checks (#9401). In plain terms: image references like nginx:1.27 can fail when the runtime cannot safely decide which registry to use.
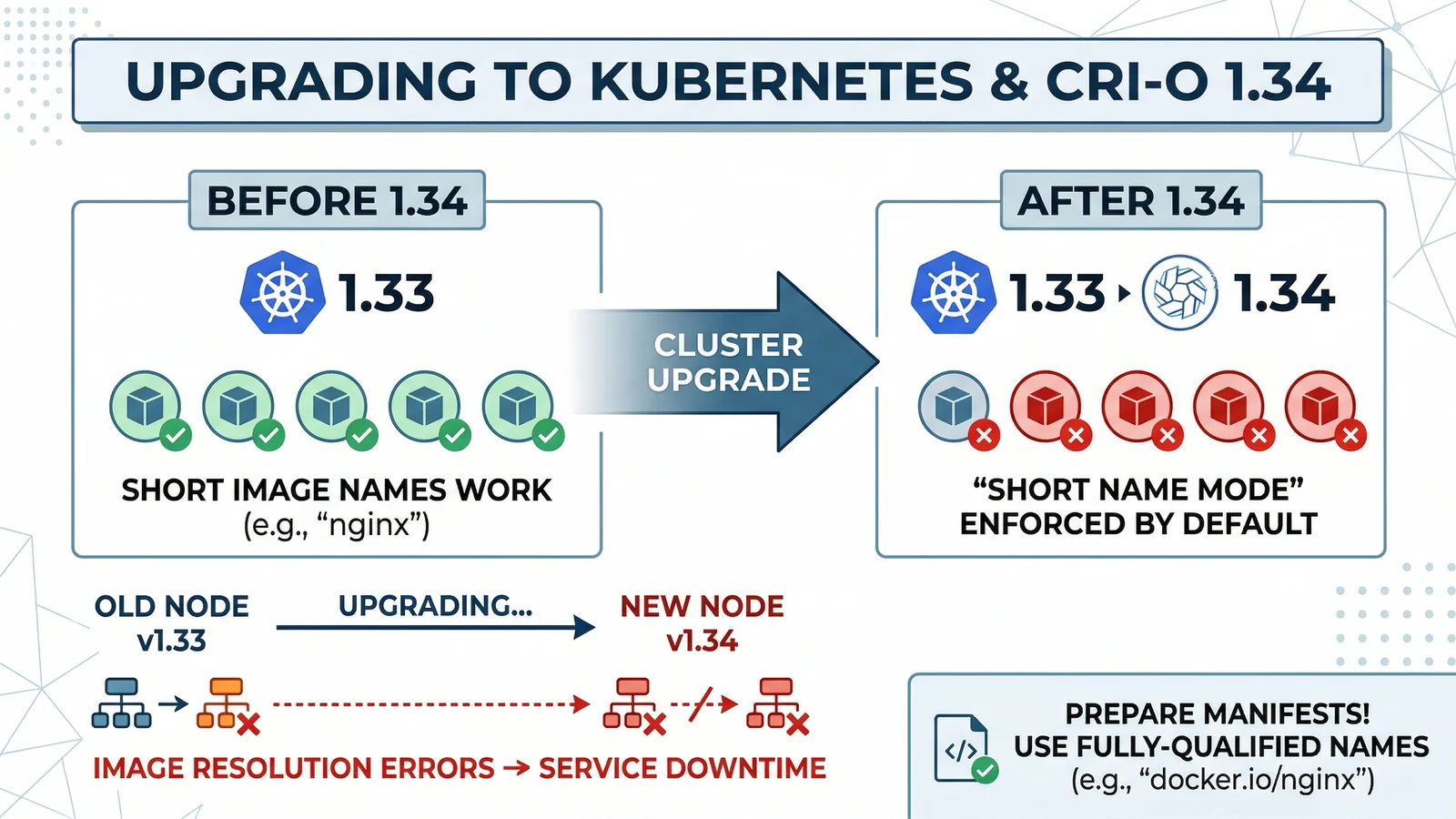
Visual summary: short names that resolved before can fail after runtime enforcement, which is why pre-upgrade remediation is critical.
Why this is actually a good change
Kubernetes documentation has long noted that if you omit a registry hostname, pull behavior depends on runtime defaults. That is convenient, but risky.
Short names increase supply-chain ambiguity:
- registry search order can differ by node/runtime config
- a typo or unexpected registry precedence can pull the wrong image
- namespace squatting risk increases when unqualified search registries are used
So while this hurts during upgrades, it pushes clusters toward safer and more deterministic image sourcing.
Who is most likely to break
You are in the risk zone if all of the following are true:
- Kubernetes control plane/nodes are on 1.34.x
- nodes use CRI-O 1.34.x
- workloads or Helm values still use short image names (for example,
redis:8,myorg/app:1.2.3,busybox)
If you run containerd, behavior may differ, but fully qualified image names are still the safest cross-runtime baseline.
Fast mitigation playbook
1) Permanent fix (recommended)
Use fully qualified image references everywhere:
- include registry host + repository path + explicit tag (or digest)
- example:
docker.io/library/nginx:1.27.5 - example:
ghcr.io/org/service:v2.4.1
2) Pre-upgrade audit (very practical)
Scan Helm values, manifests, and CI templates before upgrading nodes:
rg -n "repository:|image:" charts/ -g "*.yaml"Then fail CI for any non-qualified defaults.
3) Runtime-level temporary workaround (use with caution)
If you must keep legacy manifests alive during a transition window:
- tune
short-name-modeand/or aliases inregistries.conf - reduce ambiguity with explicit short-name aliases
Treat this as temporary. It restores compatibility, but keeps ambiguity risk alive.
4) Organization policy guardrail
Add admission or CI policy that rejects non-qualified image references in new changes.
This turns the incident into a one-time cleanup instead of a recurring outage pattern.
Suggested upgrade checklist
- Audit all charts/manifests for short image names.
- Convert to fully qualified references.
- Test on a staging cluster with the same runtime as production.
- Roll node pools in waves and monitor pull/image errors.
- Keep runtime fallback only as rollback protection, not as final state.
HelmForge status
All HelmForge charts are already aligned with the corrected pattern: image repositories are published with fully qualified references (explicit registry host), avoiding short-name resolution ambiguity by default.
References
Newsletter
Get the next post in your inbox
Join the HelmForge newsletter for Kubernetes insights, chart updates, and practical operations tips.